
Kafka
링크드인에서 개발한 오픈소스 프로젝트. 데이터 운송 매커니즘. 데이터 흐름에 몸을 맡겨보자.
- 메시징.
- 활동 추적.
- 다양한 위치에서 메트릭 수집.
- 애플리케이션 로그 수집.
- 최근에는 스트림 처리.
- 마이크로 서비스 발행/구독…
사용법
소스 시스템과 타겟 시스템 사이에 카프카를 둔다.
| 이름 | 예시 |
| 소스 시스템 | 웹사이트 이벤트, 가격 데이터 등 사용자 상호 작용 → 데이터 스트림 생성 |
| 타깃 시스템 | 데이터베이스, 분석 시스템, 이메일 시스템, 감사 시스템 |
- 소스 시스템은 카프카에 데이터를 전송한다.
- 타깃 시스템이 데이터를 받아야할 경우 Apache Kafka 로부터 받는다.
예시
- 넷플릭스를 보는 동안 Kafka 를 사용해 실시간 추천 사항 적용.
- Uber 에서 사용자,택시 여행 데이터를 실시간으로 수집하고 수요 계산, 예측. 실시간 요금 계산.
- LinkedIn 에서는 스팸을 방지하고 사용자 상호 작용을 수집해 실시간으로 더 나은 관계 추천
Kafka Topic
Kafka 클러스터 안에 있는 데이터 스트림. 한 클러스터에는 많은 토픽이 있을 수 있다.
- 데이터 스트림을 뜻한다. 테이블과 비슷하지만 제약 조건이 없다.
- 원하는 건 모두 Kafka topic 에 전송할 수 있으며 데이터 검증이 없다..!
- 이름을 통해 토픽을 식별한다.
- 모든 종류의 메시지 형식을 지원한다. (Json, Avro, txt, binary …)
Data Stream
카프카 토픽 안에 있는 메시지들의 순서
- 카프카를 데이터 스트리밍 플랫폼이라고 부르는 이유. → 토픽을 통해 데이터 스트림을 만드니까!
Partitions

토픽을 파티션들로 분할할 수 있다. 예시로 하나의 토픽이 100개의 파티션으로 구성될 수 있다.
offset
파티션이 가지는 id
중요 사항
- 토픽은 immutable 이므로 데이터를 파티션에 기록하면 변경할 수 없다.
- 삭제 X , 변경 X , 오직 기록만 가능.
- 데이터는 일정 시간만 유지된다. 기본값은 일주일.
- 오프셋은 특정한 파티션에만 의미가 있다.
- 파티션 0의 오프셋3과 파티션 1의 오프셋3은 다르다.
- 앞의 메시지가 삭제되었어도 그 오프셋을 재사용할 수 없다.
- 메시지 순서가 한 파티션에서만 보장됨.
- 각 파티션에는 메시지가 있고, 오프셋 순서로 그걸 읽음.
- 하지만 다른 파티션에서는 자기꺼 말고 다른 오프셋을 제어할 수 없음.
- 키를 제공하지 않으면 데이터가 Kafka 토픽으로 전송되면 그 데이터는 임의의 파티션에 할당 됨.
- 토픽은 원하는 만큼의 파티션을 가질 수 있으나. 토픽에 맞는 적절한 파티션 갯수가 있음.
프로듀서
어느 파티션에 기록할지 결정하며 파티션과 토픽에 데이터를 기록한다.
- Kafka 가 파티션에 기록하는 것이 아니라, 프로듀서가 기록하며 결정한다.
- 파티션 복구도 얘가 한다.
메시지 키
프로듀서가 메시지 안에 갖고 있는 메시지 키. 메시지 자체가 데이터를 보유할 수 있음. 그게 메시지 키. (문자 바이너리 뭐든 가능)
- 키 == null ? → 데이터 라운드 로빈으로 저장 (순서대로)
- 자동 로드밸런싱
- 동일한 키를 공유하는 모든 메시지들은 해싱 전략때문에 같은 파티션에 등록 됨.
메시지 구성
- 키
- 밸류(메시지 값)
- 메시지 압축 매커니즘 (메시지 압축이 가능하므로 압축을 원한다면 추가)
- 헤더 (키, 값 쌍을 가진 리스트)
- 파티션, 오프셋
- 타임스탬프
이렇게 구성된 메시지가 Kafka 로 전송되어 저장 됨.
Kafka Message Serializer
우리 메시지를 직렬화(데이터→바이트) → 프로듀서로부터 입력값으로 직렬로 된 바이트만을 받고 출력값으로 바이트 값을 컨슈머에게 전송한다.
- 키, 값으로 이루어진 객체가 있으면 KeySerializer 를 통해 직렬화함(to Binary)
- 카프카 파티셔닝
- 레코드를 받아서 어느 파티션에 저장할지 지정.
- 키 해싱 프로세스는 파티션에 대한 키 매핑을 결정하는 데 사용.
- 기본으로 murmur2 알고리즘으로 해싱된다.
- 키의 바이트를 확인하고 알고리즘을 적용해서 타깃 파티션이 어떤 파티션인지 알아냄.
Consumers
토픽에서 데이터를 읽기 위해 사용함.
- 카프카 브로커, 서버에 요청을 보내고 응답을 받기 위한 → pull 모델 구현
- 데이터를 컨슈머에게 푸싱하는 건 Kafka 브로커가 아니라 → 풀 모델.
- 파티션에서 데이터를 읽는 컨슈머는 자동으로 어떤 브로커에서 읽을지 알게 됨.
- 브로커가 고장나면 컨슈머가 복구법도 알음.
- 파티션 데이터는 순서대로 읽힘 : 정순
- 파티션으로부터 데이터를 읽고 변환한다.
Deserializer
파티션으로부터 데이터를 읽어와 역직렬화 한다.
- binary → objects/data
- Kafka 에 포함되어있고 컨슈머가 사용하여 역직렬화한다.
- 프로듀서에는 Serializer, 컨슈머는 Deserializer 가 있음.
- 컨슈머는 키 값 포맷을 미리 알고있어야 함. → 토픽이 생성될 때 프로듀서가 전송하는 데이터 타입을 변경하지 말아야 함. → 안 그럼 컨슈머가 아는 타입과 달라서 역직렬화 못함.
- 토픽 자료형 변경하고 싶다면 새 토픽을 만들어야 함.
컨슈머 그룹

말 그대로 컨슈머 그룹, 애플리케이션 안에 컨슈머들이 그룹 형태로 데이터를 읽을 것이다.
- 이렇게 한 컨슈머 그룹에 여러 컨슈머들이 있고 각자 맡은 파티션에서 데이터를 읽어온다.
- 그룹이 토픽 전체를 읽어온다.
만약 파티션 갯수보다 컨슈머가 많다면?
- 컨슈머가 파티션 하나씩 맡고 남은 컨슈머는 비활성화(stand-by) 상태가 됨.
하나의 토픽에 다중 컨슈머 그룹이 있다면?
- 이렇게 사이좋게 나눠서 읽는다.
이렇게 다수의 컨슈머 그룹이 있는 이유?
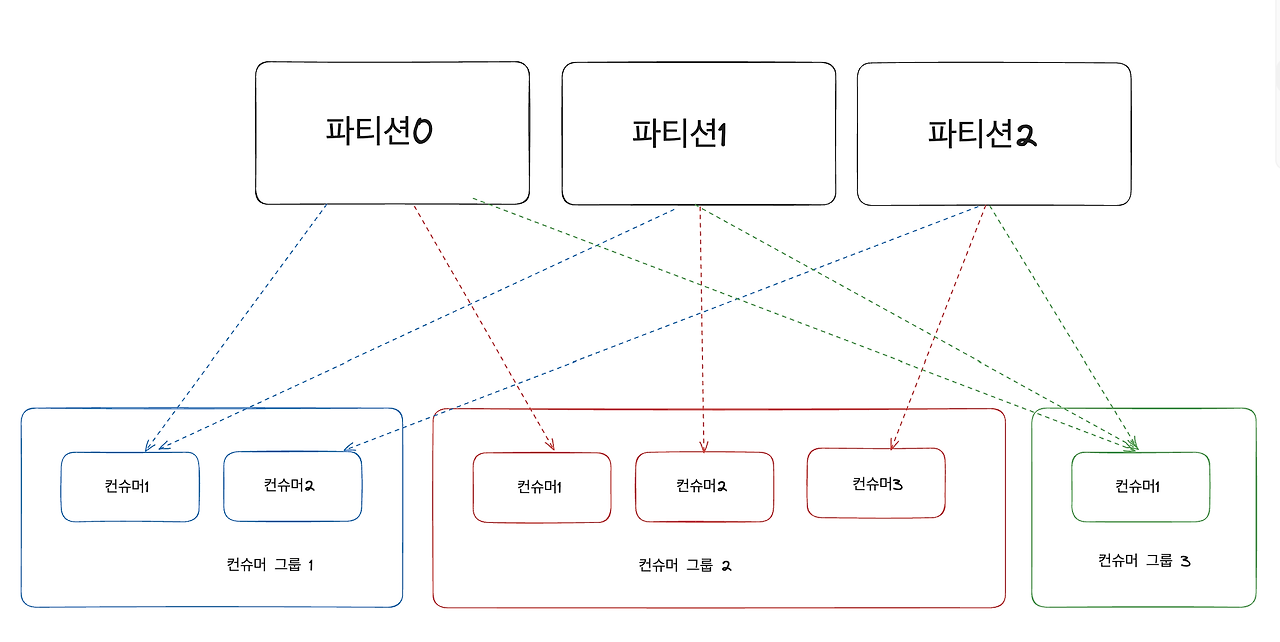
- 서비스당 하나의 컨슈머 그룹을 갖는데, 데이터 스트림 하나에 여러 서비스가 있다면 (예: 위치서비스, 알림서비스) 컨슈머 그룹이 여러 개 있을 수도 있다.
컨슈머 오프셋
컨슈머 그룹 내에서 지정할 수 있음. 컨슈머 그룹이 읽고 있는 오프셋을 저장한다.
- Kafka 토픽 내부에서 __consumer_offsets 라는 이름으로 가지고있는다.
- 컨슈머는 오프셋을 커밋하고 읽는다.
- 데이터 처리를 컨슈머가 완료하면 종종 오프셋을 커밋하고 내부 오프셋 토픽에 기록함.
- 어디까지 성공적으로 읽었는지 브로커에게 알려줄 수 있음.
- 만약 컨슈머가 죽어도 읽었던 곳에서부터 다시 읽을 수 있다!
커밋 설정
- 세 가지 모드가 있음.
At least once (default)
- 최소 한 번은 자동으로 커밋됨.
- 처리가 잘못되면 메시지를 다시 읽을 수 있음. (메시지 읽기 반복 가능)
- 멱등성인지 확인해야함 → 여러 번 반복해도 프로그램이 달라지지 않는가?
At most once
- 메시지를 받자마자 오프셋이 커밋됨
- 잘못 읽어도 다시 못읽음 → 읽기 전에 커밋해버림.
Exactly once
- 반드시 한번만 읽음.
- 카프카 내에서 처리할 때는 트랜잭션 api 사용 가능. (kafka 스트림 api)
- 카프카 외부에서 처리할 때는 멱등 컨슈머를 사용해야 함.
→ 오프셋을 커밋하는 방법이나 시기에 모드를 정해서 사용하기.
브로커
데이터를 받고 보내는 서버. Kafka 클러스터는 다수의 브로커들로 구성되어 있다.
- ID (정수) 로 식별
- 브로커 101 , 브로커 102, 브로커 103 …
- 각각의 브로커에는 특정한 토픽 파티션만 담긴다.
- Kafka 브로커에 연결하면 클라이언트,프로듀서,컨슈머가 전체 Kafka 클러스터에 자동으로 연결됨.
- 브로커 하나에만 연결하면
- 그 브로커가 모든 브로커(부트스트랩 서버) 정보를 줌.
토픽 복제
브로커가 다운되어도 다른 브로커에 데이터 사본이 있어서 그걸 주고 받을 수 있다. 로드밸런서 개념이다.
- 복제를 하더라도 리더 브로커가 있으며, 기본 설정으로는 리더브로커에게만 데이터를 주고 또 요청한다.
컨슈머 레플리카 페칭
컨슈머가 가장 가까운 레플리카에서 읽게 해주는 기능. (도 있다.)
프로듀서 확인
프로듀서는 데이터 쓰기를 확인받을 수 있다. 세 가지 셋팅이 있음.
| acks | 설명 | 데이터 유실 유무 |
| 0 | 프로듀서가 확인을 기다리거나 요청하지 않음. | 유실 가능. |
| 1 | 프로듀서가 파티션의 리더 브로커가 확인하기를 기다림. | 데이터 유실 제한. |
| all | 모든 레플리카 리더가 쓰기를 확인하라고 요청. | 데이터 유실 없음. |
토픽 내구성
- 만일 복제 계수가 3인 토픽이 있다면 2개의 브로커가 손실나도 데이터를 보존할 수 있다.
- 복제계수 n 개를 선택한다면, 최대 n-1 개의 브로커를 잃어도 데이터 사본이 클러스터 어딘가에는 존재한다.
주키퍼
브로커들을 관리하는 소프트웨어.
- 브로커가 다운될 때마다 새로운 리더를 선출하는 걸 돕고
- 변경 사항이 있으면 브로커들에게 알림을 전송해줌. → 브로커 다운, 토픽 삭제…
- 원래는 카프카를 주키퍼 없이는 사용할 수 없었음.. 그러나 Kafka 3.x 부터는 주키퍼 없어도 실행할 수 있음.
정보
- 주키퍼는 홀 수로 작동함.
- 하나는 리더, 나머지는 팔로워로 사용. → 하나는 쓰기, 나머지는 읽기
- 오래된 카프카 버전에서는 컨슈머를 이용해 오프셋을 주키퍼에 저장했었다.
- 하지만 지금은 오프셋을 내부 토픽에 저장함!
사용 여부
- 브로커를 관리한다면, 카프카 4.0 전까지는 주키퍼 없이 카프카 사용 불가.
- 그냥 최신 카프카를 사용하려면 주키퍼 사용 ㄴㄴ 하세용~~
Kafka KRaft 모드
카프카가 주키퍼에 대한 의존성을 제거하려고 노력했고 대신 이 모드를 사용하라고 하네요~.
주키퍼와 차이
- 주키퍼는 리더가 있고 나머지는 팔로워
- Kafka 브로커들이 있고 그 중에 하나가 리더가 됨
- KRaft 가 성능이 더 좋다.
- 제어 셧다운 시간 우수
- 무제어 셧다운 후의 복구 시간 우수
'개발공부 개발새발 > etc' 카테고리의 다른 글
| HTTP ) HTTP1.1 과 HTTP2 의 차이는 무엇일까? (0) | 2024.12.23 |
|---|---|
| SSE ) Server-Sent Message (0) | 2024.02.26 |
| 배웠던 것을 정리하는 그런 notion 을 작성했다면 믿으시겠습니까 ? (0) | 2023.07.17 |
| 클라우드 교육 정리와 후기! (0) | 2023.07.16 |
| Mac M2 칩에서 오라클 실행 저장용 (0) | 2023.05.09 |

